Semantic Web (Nam-ı Diğer Web 3.0)
“Web için bir hayalim var; bilgisayarlar, web üzerindeki tüm veriyi (içerikler, bağlantılar ve insanlarla bilgisayarlar arasındaki işlemler), analiz etme kabiliyetine sahip olacaklar. Henüz hazır olmasa da ‘Semantic Web’in yapılması mümkün!. Hazır olduğunda ise günden güne ticaret yöntemlerimiz, bürokrasi ve günlük yaşamlarımız birbiri ile konuşan makinalar tarafından idare edilecek. İnsanlığın asırlardır konuştuğu ‘zeki araçlar’ gerçek olacak.” Tim Berners-Lee
Söz büyüğündür der atalarımız, bu nedenle lafıma, internetin babası, semantic web kavramını ilk ortaya atan ve gerçekleşmesi için bir yol haritası bize sunan üstad Tim Berners-Lee ile başlayalım istedim. Geçtiğimiz yıl Web 2.0’ı anlamaya ve kavramaya çalışırken, geçen Kasım(Kasım 2006) ayında Web 3.0 adıyla yeni bir kavram duyduk. Neymiş bu Web3.0 dediğimizde eski bir terim ile semantic web kavramı ile karşılaştık. Aşağıdaki grafikte Web 4.0’ın bile adının geçtiğini dikkatinizi çekmek isterim. O da ayrı bir makale konusu olduğundan lafı çok uzatmadan neymiş bu semantic web gelin beraber inceleyelim.

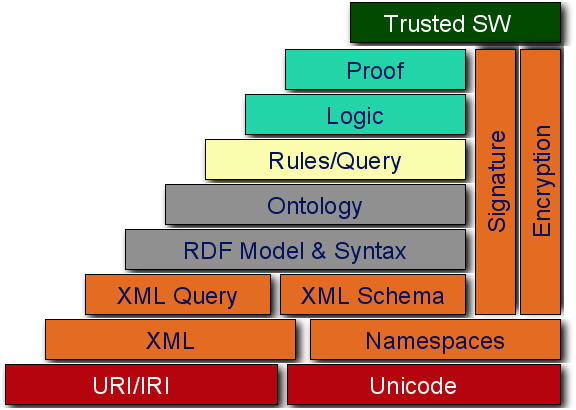
Semantic Web nedir? Web 1.0’ da sayfalar insanların okuyup anlayabileceği şekilde hazırlanıyordu. Web 2.0 ile verileri etiketlemeye ve AJAX tekniği ile web sayfaları kullanımı kolay ve hızlı bir hal aldı. Makinelerin birbirleri ile konuşabilmesi için XML çıktılar veren metodlar ürettik. SOAP ve benzeri protokoller inşa ettik. Tim Berners Lee’nin telafuzunu ettiği Web 3.0’a geçiş için gerekli olan hazırlıkları yaptık. Başında ’e’ harfi koyarak bürokratik işleri bizim için makinalarin yapmasını sağladık. Bu makinaların konuştuğu yerlerde karar gerektiren noktalara ise insanlar koyduk. Web 3.0 ile makinalar bizi daha önceki davranışlarımızdan ve konuştuklarımızdan anlamaya ve çözümler üretmeye çalışacak. Makina-Makina ile karar gerektiren kısımlarda da konuşabilecek. Bu konuyu aşağıdaki gibi bir örnek ile açıklama çalışayım. Hayal edin!, diyelim ki cumartesi günü basketbol maçı yapacaksınız ve basketbol maçı yapmak için bir yer arıyorsunuz. Arama motoruna “istanbul’da cumartesi günü uygun basketbol sahası” şeklinde bir arama yaptınız. Arama motoru cümleyi yorumladı ve size sadece basketbol sahalarının bulunduğu siteleri getirdi. Hatta istanbul kriterinide girdiginiz icin sadece Istanbul’dakileri sahaları getirdi. İşte size semantic web budur. Semantic web zayıf bir yapay zeka kullanır. İşi biraz yokuşa sürelim ve yapay zeka kavramını devreye sokalım. Arama motoru hava durumunu inceleyip, cumartesi günü İstanbul’da yağış olduğu için sizi uyararak üstü açık olan basketbol sahalarını görmek isteyip, istemediğimi sorabilir. Yada sadece üstü kapalı basketbol sahalarını listeleyebilir. İşte yapay zeka ile semantic web arasındaki fark budur. Bu örnekten sonra gerçekleşmesi için neler gerektiğine bakalım. Peki makinalar, siteleri bizim gibi nasıl anlayacak? Makinaların bizi anlaması için gerçekten çok fazla veriye ihtiyaç var. İnternette bu veriler yeterli oranda mevcut. Fakat dağınık ve hiçbirinin bir diğerine makinaların anlayabileceği bir ilişkisi yok. Yani verilerin toplanması ve yorumlanması ve daha sonraki sorgulamalar için depolanması gerekiyor. Şimdi bu 3 temel öğe altında neler yapılıyor yada yapılması gerekiyor onları inceleyelim. 1) Verileri Anlamlı Bir Şekilde Ayrıştırma
a) Etiketleme Yöntemiyle İçeriği Toplamak:Web 2.0 ile beraber, hayatımızda etiketleme(tag) kavramı ortaya çıktı. Böylece makinaların bir sürü veri içinden biz insanlar için öncelikli ve gerekli olan bir veri alanı oluşturmuş olduk. Etiketlemenin en büyük avantajı, kelimeler arasındaki ilişkilerin insanlar tarafından sağlanıyor olması. Mesela, kartal resimlerinin bulunduğu bir siteyi etiketlemek istesek, etiketimiz sanırım “kartal kuş fotoğraf ” gibi bir etiketler dizisine sahip olurdu. Böylece sizin botlarınızın yapacağı işi insanlar yapmış olacak. %20’ye %80 kuralını bilirsiniz. Web üzerindeki verinin %20’si gerçekten insanların ihtiyacı olan veridir. Geri kalan %80 ise çöp veridir. Buna dayanarak, insanların girdiği veri tamamiyle %20’lik olan gerekli alana girecektir. Etiketlemek, aynı dizideki etiketlere göre bir anlam ilişkisi bulunur. Yukarıdaki örneğimizi ele alalım. Kartal bir kuştur. Ve sitedeki veriler kuş resimleridir. Çok güçlü olmasada kendimize küçük bir semantic web uygulaması oluşturduk. Tabii daha yapılması gereken çok iş var. Bu sadece bir başlangıç olduğunu unutmamak gerekir.Etiketleme ile ilgili araç-amaç ilişkisine şuan aklıma gelen en güzel örnek, Google Image Labeler. Google’ın amacı etiketi olmayan resimleri etiket altında toplamak. Ama bir sürü etiketlenmesi gereken resim var. Bu iş için nasıl bir şey yapmalı? İnsanlar eğlenceyi sever. Oyunlar eğlencelidir. Neden bu işi oyun olarak sunmayalım düşüncesi ile ortaya çıkmıştır.b) Alana Göre İçeriği Toplamak:Daha öncede söylediğim gibi semantic web için büyük bir içerik gerekli. Google’ın veri madenciliği yapmasının sebebi bu aslında. Google’ın hedefi, Hakia gibi semantic web. hatta belki daha da ileriye giderek yapay zeka (Google’ın Master Plan’ın çizili olduğu kocaman yazı tahtasını incelemiş olanlar “AI Developer” hayallerini bilirler.) konuları. Fakat Google, Hakia’dan farklı olarak taklit ederek öğrenme yöntemini izliyor. Belli bir alana (domain) yönelik çıkardığı servisler bu amaca hizmet ediyor. İsterseniz bu servislerden bir kaçına bakalım; 1) GMail; epostaların hayatımıza girmesi ile çok önemli veriler, eposta kutularımızda toplanmaya başladı. Üye olduğumuz yerler (ilgi alanlarımız) ve şifreleri, özel yazışmalarımız, konuşama şeklimiz vs.. Neden google’ın bir dosyayı silmenizi istemediğini 2.8 GB alan verdiğini düşünüyorsunuz. Hatırlarsanız gmail ilk çıktığında davetiye yolu ile çalışıyordu. Yani insanların birbiri ile olan ilişkilerinide tutmakla işe başladılar.2) GTalk; eğer bir bot yazacak olsanız. Dünyada bir çok insanın, sorulara karşı verdiği cevapları loglasanız ne elde ederdiniz. Birçoğumuz konuşurken çeşitli hazır kalıpları kullanırız.- Naber- İyilik, sendenBu kalıp ve benzeri kalıpları sürekli kullanıyoruz. GTalk Google için inanılmaz bir insanı taklit aracı.3) Google Image Labeler; oyun görünümlü servis. Web kullanıcıları bedavaya veri girişi için kullanamanın en etkili yolu :)c) Anlamlı İndeksleme ve Dilbilgisi:Hakia’dan yola çıkmak bu konu başlığı için çok doğru olacak. Yahoo ve Google’ın pagerank algoritması verileri kelime anlamına göre indekslemez. Metaya göre indeksler. Bu nedenle yukarıda söylediğimiz alana gore içerik toplama yöntemiyle ilerliyorlar. Anlamlı indeksleme için ise özellikle Google’ın çalışmaları olduğunu site çeviri servisi gibi bazı servisler bize ipucu veriyor.Hakia’nın çalışmaları veriyi anlamlandırarak indeksleme temeline dayanıyor. Özellikle yaptıkları OntoSem (Ontological Semantics) adındaki teknolojileri bu işe yarıyor. OntoSem, Prof. Victor Raskin’in akademik çalışması; bu konunun amacı doğal dilleri anlamlandırma temeline dayanıyor. Yani doğal diller üzerinde işlemler yazılım mühendisliğine dayanıyor.Bu ciddi zorlukları olan bir konu. Cümle öğelerine bölünerek anlamlandırıldığı gibi tipine görede bir ontology ağacında yerini alıyor. Böylece kelimeler ağaçtaki yerine gore indeksleniyor. Yapay zekanın önemli konu olacağı şüphesiz bir konu. Hakia’nın diğer çalışmalarına buradan erişilebilir.
2) Ayrıştırılan Verilerin Bir Yerde Toplanması Verileri toplamak için en yaygın yöntem olarak, RDF kullanılmaktadır. RDF(Resource Description Framework) W3C’ bulduğu bir ilişkilendirme çatısıdır. Şimdiden birçok kurum ve kuruluş tarafından standart olarak kabul edilmiş ve kullanılmaya başlamıştır. Dilbilgisindeki özne, nesne, yüklem bağlantısına benzeyen bir söz dizimine sahiptir. Yukarıda daha önce verdiğimiz örneğe geri dönersek; İstanbuldaki basketbol sahalarını listelemek. İTÜ, İstanbul’un en güzel basketbol sahasına sahiptir. Burada ‘İTÜ’ özne, ‘İstanbul’ nesne, ‘en güzel basketbol sahasına sahiptir’ ise yüklemdir. Şimdi bunu RDF içinde görelim.
<rdf:RDFxmlns:rdf=“http://www.w3.org/1999/02/22-rdf-syntax-ns#"xmlns:dc=“http://netology.org/dc/elements/1.1/"><rdf:Description rdf:about=“http://etkinlik.itu.edu.tr/basketbol"><dc:location>İTÜ</dc:location><dc:city>İstanbul</dc:city></rdf:Description></rdf:RDF>
http://netology.org/dc/elements/1.1/ adresinde location ve city tanimlanmistir.  Yukarıdaki örnekten de anlaşılacağı üzere RDF karışık bir yapıya sahiptir. Bu sebeple OWL(Web Ontology Language) kullanılmaktadır. OWL ontology grupları oluşturmaya yarar ve RDF’ten çok daha kolaydır. Aşağıda yaşlı kadınların sahip olduğu kediler ile ilgili bir örnek verilmiştir.
Class(a:old_lady completeintersectionOf(a:person a:female a:elderly))Class(a:old_lady partial intersectionOf(restriction(a:has_pet allValuesFrom (a:cat))restriction(a:has_pet someValuesFrom (a:animal))))Class(a:cat_owner complete intersectionOf(a:personrestriction(a:has_pet someValuesFrom (a:cat))))
1) GMail; epostaların hayatımıza girmesi ile çok önemli veriler, eposta kutularımızda toplanmaya başladı. Üye olduğumuz yerler (ilgi alanlarımız) ve şifreleri, özel yazışmalarımız, konuşama şeklimiz vs.. Neden google’ın bir dosyayı silmenizi istemediğini 2.8 GB alan verdiğini düşünüyorsunuz. Hatırlarsanız gmail ilk çıktığında davetiye yolu ile çalışıyordu. Yani insanların birbiri ile olan ilişkilerinide tutmakla işe başladılar.2) GTalk; eğer bir bot yazacak olsanız. Dünyada bir çok insanın, sorulara karşı verdiği cevapları loglasanız ne elde ederdiniz. Birçoğumuz konuşurken çeşitli hazır kalıpları kullanırız.- Naber- İyilik, sendenBu kalıp ve benzeri kalıpları sürekli kullanıyoruz. GTalk Google için inanılmaz bir insanı taklit aracı.3) Google Image Labeler; oyun görünümlü servis. Web kullanıcıları bedavaya veri girişi için kullanamanın en etkili yolu :)c) Anlamlı İndeksleme ve Dilbilgisi:Hakia’dan yola çıkmak bu konu başlığı için çok doğru olacak. Yahoo ve Google’ın pagerank algoritması verileri kelime anlamına göre indekslemez. Metaya göre indeksler. Bu nedenle yukarıda söylediğimiz alana gore içerik toplama yöntemiyle ilerliyorlar. Anlamlı indeksleme için ise özellikle Google’ın çalışmaları olduğunu site çeviri servisi gibi bazı servisler bize ipucu veriyor.Hakia’nın çalışmaları veriyi anlamlandırarak indeksleme temeline dayanıyor. Özellikle yaptıkları OntoSem (Ontological Semantics) adındaki teknolojileri bu işe yarıyor. OntoSem, Prof. Victor Raskin’in akademik çalışması; bu konunun amacı doğal dilleri anlamlandırma temeline dayanıyor. Yani doğal diller üzerinde işlemler yazılım mühendisliğine dayanıyor.Bu ciddi zorlukları olan bir konu. Cümle öğelerine bölünerek anlamlandırıldığı gibi tipine görede bir ontology ağacında yerini alıyor. Böylece kelimeler ağaçtaki yerine gore indeksleniyor. Yapay zekanın önemli konu olacağı şüphesiz bir konu. Hakia’nın diğer çalışmalarına buradan erişilebilir.
2) Ayrıştırılan Verilerin Bir Yerde Toplanması Verileri toplamak için en yaygın yöntem olarak, RDF kullanılmaktadır. RDF(Resource Description Framework) W3C’ bulduğu bir ilişkilendirme çatısıdır. Şimdiden birçok kurum ve kuruluş tarafından standart olarak kabul edilmiş ve kullanılmaya başlamıştır. Dilbilgisindeki özne, nesne, yüklem bağlantısına benzeyen bir söz dizimine sahiptir. Yukarıda daha önce verdiğimiz örneğe geri dönersek; İstanbuldaki basketbol sahalarını listelemek. İTÜ, İstanbul’un en güzel basketbol sahasına sahiptir. Burada ‘İTÜ’ özne, ‘İstanbul’ nesne, ‘en güzel basketbol sahasına sahiptir’ ise yüklemdir. Şimdi bunu RDF içinde görelim.
<rdf:RDFxmlns:rdf=“http://www.w3.org/1999/02/22-rdf-syntax-ns#"xmlns:dc=“http://netology.org/dc/elements/1.1/"><rdf:Description rdf:about=“http://etkinlik.itu.edu.tr/basketbol"><dc:location>İTÜ</dc:location><dc:city>İstanbul</dc:city></rdf:Description></rdf:RDF>
http://netology.org/dc/elements/1.1/ adresinde location ve city tanimlanmistir.  Yukarıdaki örnekten de anlaşılacağı üzere RDF karışık bir yapıya sahiptir. Bu sebeple OWL(Web Ontology Language) kullanılmaktadır. OWL ontology grupları oluşturmaya yarar ve RDF’ten çok daha kolaydır. Aşağıda yaşlı kadınların sahip olduğu kediler ile ilgili bir örnek verilmiştir.
Class(a:old_lady completeintersectionOf(a:person a:female a:elderly))Class(a:old_lady partial intersectionOf(restriction(a:has_pet allValuesFrom (a:cat))restriction(a:has_pet someValuesFrom (a:animal))))Class(a:cat_owner complete intersectionOf(a:personrestriction(a:has_pet someValuesFrom (a:cat))))
](http://farm1.static.flickr.com/250/452486876_b61b9ff7b2_o.jpg){kind=link}
- Yaşlı kadınlar muhakkak evcil bir hayvana sahiptir.
- Yaşlı kadınların evcil hayvanları kedilerdir.
- Kedilerin sahibi yaşlı kadınlardır.
Daha kapsamlı bir örneğe buradan erişebilirsiniz. 3) Anlamlı Verilerin İçinden Sorgulama SPARQL en çok kullanılan sorgulama dilidir. Hakia’nında bu konuda kendi geliştirdiği QDEX(Query Detection and Extraction) adında bir teknoloji ile bu işi yapar. Semantic Web İçin Başlangıç Noktası Neden Arama Motorları? İnsanların hayatında her zaman büyük yada küçük bir hedefi vardır. Hedeflere ulaşmak için çeşitli çözüm ararlar. İşte anahtar kelime bu, Aramak. Hayatımız hep birşeyler arayarak geçer. Bir insanın 3 tip hedefi vardır. a) İhtiyaç b) Statü c) Eğlence Arama motorları neden hayrına bize böyle bir hizmet sağlıyor? Neden böyle bir amaçları var. Arkasında ne yatıyor olabilir? İnsanların aradıklarını bulmak için ne aradıklarını bilmeniz gerekir. İnsanların istedikleri şeyleri bildiğinizi düşünün. Bu tanrısal bir erdemdir. Ve gerçekten büyük bir güçtür. Çünkü bazı isteklerimizi, başkalarının öğrenmesi vicdanen bizi rahatsız edebilir. Sorumuza tekrar geri dönelim; neden böyle bir hizmet için mücadele ediyorlar? Bence gelecekte bilgi hür olacaktır. Şu an çok saçma bir şekilde DNA’larımız, bazı hastalıklar patent altına alınmakta, birilerinin mülkiyeti altına girmektedir. Çeşitli fikir mülkiyetleri orta atılmaktadır. Bu fikri yıkmak adına CreativeCommon adı altında bir oluşum bulunmaktadır. Fikir mülkiyeti saçma bir fikirdir. Hepimizin bulduğu şeyler çevremizdeki etkenler ve duygularla yaratılmıştır. Bilgi kimseye ait değildir. Şuanki kapitalizm etkisindeki dünyanın bu fikri kabul etmesi güç olduğu muhakkak. Fakat düşünün bundan 20 yıl önce Richard Stallman özgür yazılım felsefesini ortaya attığında da insanların bu görüşü kabul etmesi pek kolay olmadı. Peki arama motorlarının amacı yukarıda saydıklarımız mı dersiniz? Eğer ellerindeki tüm bilgiyi herkese açacaklarsa evet amaç bilgi özgürlüğü denebilir. Ama bu işlerle uğraşanlar akademik kurumlardan daha çok ticari kuruluşlardır. Ve hepsinin bir gayesi bulunmaktadır. Tehlikenin farkında mısınız? Gelecekte hepimizin bir profili olacak! Şu an kullandığımız kredi kartları, cep telefonları yada çeşitli internet servislerinde bu profiller yavaş yavaş oluşuyor. Nereden hangi ihtiyacımızı alıyoruz, nerelere gidiyoruz. Hepsi kayıt altına girmeye başladı Köleliğin formları değişmeye başladı. Artık birkaç beton yığını ile örülü değiliz. Akıllarımız köleleştiriliyor. Pazarlamacılar(marketing) Semantic Web konusuna yakından takip ediyor. Ağızlarının suyu akıyor. Bu insanlardan bilgiyi korunmanın yollarını aramak, bu kurumlara karşı özgür projelerle kırmaya çalışmak gerekiyor. Yukarıda söylenilenler daha çok ütopik ve komplo teoriler içeriyor. EPIC 2015’te benzer bir durumdan söz ediyor. Ama gerçek payı yok mu? Bunu yapmayacaklarını kim iddaa edebilir. Internette kişisel bilgilerimizi içeren birçok küçük servis mevcut. Göze çarpanlar Google, Yahoo gibi devler tarafından satın alınıyor. Bu bilgilerde devlerin veri madenlerine katılıyor. Peki hepsini almak mümkün mü? Elbetteki hayır. İşte Yahoo tarafından önerilen çözüm. Mashup’lar. Mashup, melez servislerdir. Birkaç servisin birleşmesi ile ortaya çıkar. Bu fikir çok güzel olmakla birlikle, şirketlerin özgür yazılım felsefesinin onlar için zehirli olan tarafını atıp, açık kaynak adı altında yumuşatarak nasıl bedava insan gücü elde ettilerse, aynı şey mashup fikri ile bu küçük servislerin altyapılarını açmalarına zorlayacaktır. İnternet Yaşamdır Kurucusu olduğum Netology Yazılım Vakfı, internetin yaşamımızdaki vazgeçilmez yerinin farkında olan bir oluşum. İnternetin tamamen kamu yararına kullanılması için yeni teknolojiler geliştirmeyi hedeflemektedir. Yakında bu konudaki çalışmalarımızı http://www.netology.org adresinden duyuracağız. Üstadlar (hackers) tarafından bugünkü halini alan intenet; şuan özgür olduğumuz ve global dünya fikrinin gerçekleştiği tek yer. Onu kimsenin kötü emellerine alet edip kirletmesine izin veremeyiz. İnternet yaşamdır ve bir devletin yada kuruluşun değil tüm kamunun malıdır!